client-go 源码学习系列:
- client-go 之概述篇
- client-go 之 Informer 篇
- client-go 之 WorkQueue 篇
前言
在上篇文章中主要讲解了 client-go 中主要源码目录结构,client-go 提供的各种客户端接口,并且简单介绍了 client-go 中 informer 机制中各组件的功能,以及 client-go 中提供的 WorkQueue 的几种接口。而这篇文章,将从源码的角度和大家详细的分析下 Informer 中主要组件的实现。
Informer 介绍
在 client-go 中提供了各种访问 API 资源的客户端接口,以便使用者可以方便的操作存储在 ETCD 中的各种资源对象。为了能够快速的获取到对象的变化,K8S 提供了 Watch 的 API 去监听资源在 ETCD 中的变化事件。而这里的 Watch 操作其实是客户端通过发送一个 HTTP 请求与服务端建立一个长连接,并通过 Chunked transfer coding (即分块传输编码)的传输机制实现的。
而一般我们很少直接使用 Watch API 去监听资源的变化事件,因为直接使用这个 API,对于调用者是用户不友好的,为什么这么说,因为每个 Watch 都要维护一个 HTTP 长连接,因此,对于调用者来说需要处理很多异常问题,并且我们知道 Watch 只是监听 API 资源的变化事件,那其中包括添加,修改,删除事件,因此调用者还要判断事件类型,并做不同的处理;还有最重要的一点是,调用者还要自己保证如何不丢失事件。所以,对于调用者来说,如果都要自己实现,那简直是太灾难了。因此 K8S 实现了一套 Watch 操作即这里的 Informer 机制,从而使得调用者实现资源变化的监听更为简单。
首先我们来简单描述下 Informer 的实现机制。首先 Informer 中的 Reflector 组件会调用 List API 去获取所有指定资源对象信息,并存储在本地的 Store 中;然后 Reflector 组件调用 Watch API 去监听指定资源的变化事件(这里的 List 和 Watch 操作,在 K8S 中大家都叫它 ListWatch 操作);而当 ETCD 中 API 资源发生变化时,Reflector 组件将会获取到变化事件的信息,并将信息添加到一个 DeltaFIFO 的队列中;然后 Informer 组件会从这个 DeltaFIFO 队列中获取这个变化的事件信息存储到本地的 Indexer 中,并且根据事件的类型分发到提前注册好的不同的 Event Handler 中,从而调用到对应的用户实现的事件处理函数。
client-go 中提供了几种不同的 Informer:
- 通过调用 NewInformer 函数创建一个简单的不带 indexer 的 Informer。
- 通过调用 NewIndexerInformer 函数创建一个简单的带 indexer 的 Informer。
- 通过调用 NewSharedIndexInformer 函数创建一个 Shared 的 Informer。
- 通过调用 NewDynamicSharedInformerFactory 函数创建一个为 Dynamic 客户端的 Shared 的 Informer。
这里带有 Indexer 和不带 Indexer 的大家好理解写,从字面意思来看,就是一个是带有 Indexer 功能一个不带有 Indexer 功能的 Informer。而这里的 Shared 的 Informer 引入,其实是因为随着 K8S 中,相同资源的监听者在不断地增加,从而导致很多调用者通过 Watch API 对 API Server 建立一个长连接去监听事件的变化,这将严重增加了 API Server 的工作负载,及资源的浪费。比如在 kube-controller-manager 组件中,有很多控制管理都需要监听 Pod 资源的变化,如果都独立的调用 Informer 去维护一个对 APIServer 的长连接,这将导致 kube-controller-manager 中资源的浪费及增加了 APIServer 的负载,而不同控制管理者通过创建 Shared 的 Informer 则实现了这些控制管理者使用同一个 Watch 去和 APIServer 建立长连接,并在收到事件后,分发给下游的调用者。
Informer 源码分析
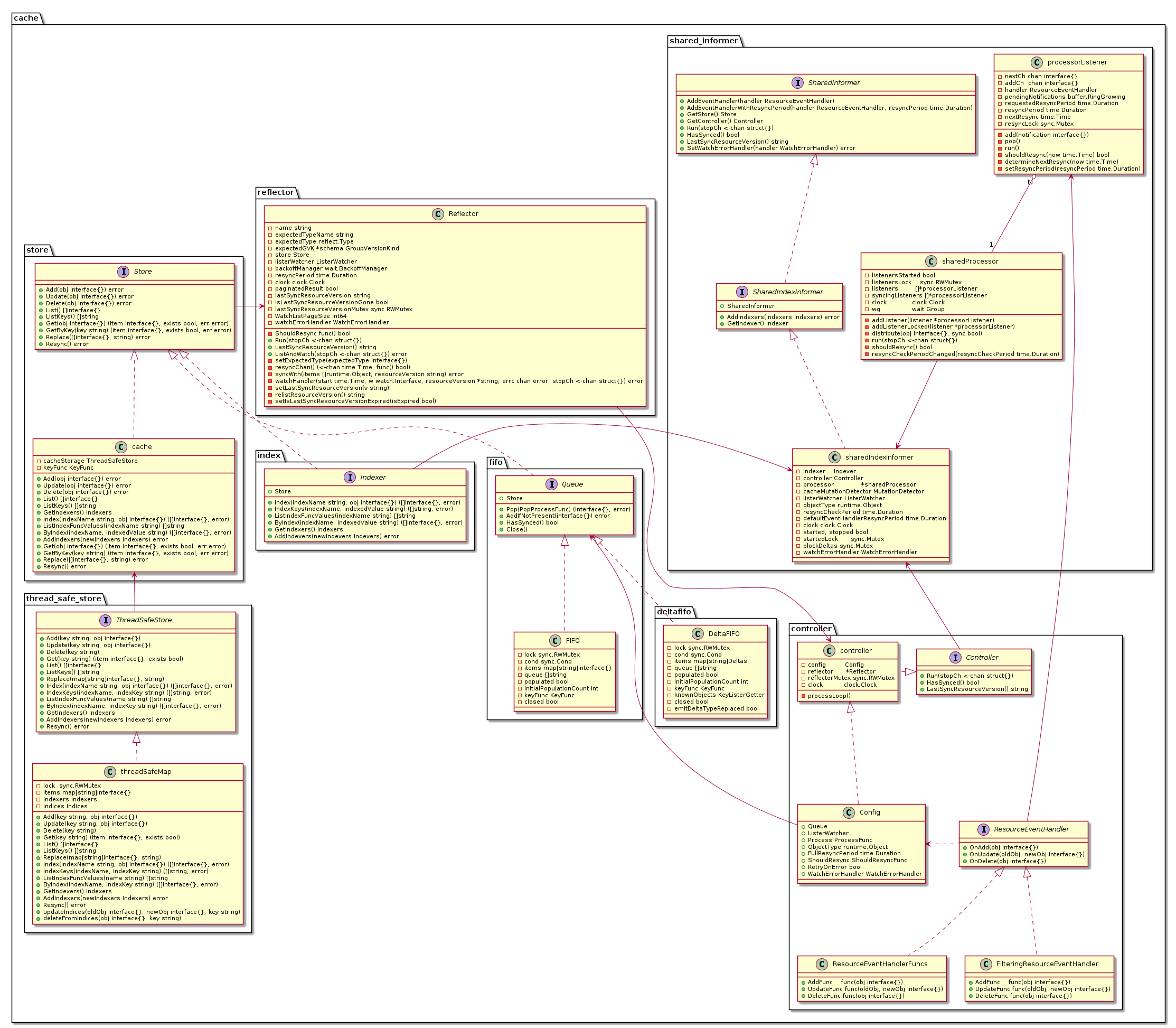
该类图主要描述了 Informer 中主要的接口和类之前的调用关系。大家可以参考这个类图去阅读源码。下面我将主要对于 Reflector,Controller 和 Indexer 部分进行分析。对于 SharedInformer,这里我将不做过多的描述,如果有兴趣的话,可以参考 SharedIndexInformer 分析.
Reflector 源码分析
从上面我的讲述,相信大家应该了解到 Informer 中 Reflector 部分的主要职能,即它通过 list-watch 机制监听来自 ETCD 中各种资源事件的变化,并将这些事件添加到一个 DeltaFIFO 的队列中让 Controller 部分去消费。
下面我们来看看 Reflector 的具体实现:
func NewReflector(lw ListerWatcher, expectedType interface{}, store Store, resyncPeriod time.Duration) *Reflector {
return NewNamedReflector(naming.GetNameFromCallsite(internalPackages...), lw, expectedType, store, resyncPeriod)
}
// NewNamedReflector same as NewReflector, but with a specified name for logging
func NewNamedReflector(name string, lw ListerWatcher, expectedType interface{}, store Store, resyncPeriod time.Duration) *Reflector {
realClock := &clock.RealClock{}
r := &Reflector{
name: name,
listerWatcher: lw,
store: store,
// We used to make the call every 1sec (1 QPS), the goal here is to achieve ~98% traffic reduction when
// API server is not healthy. With these parameters, backoff will stop at [30,60) sec interval which is
// 0.22 QPS. If we don't backoff for 2min, assume API server is healthy and we reset the backoff.
backoffManager: wait.NewExponentialBackoffManager(800*time.Millisecond, 30*time.Second, 2*time.Minute, 2.0, 1.0, realClock),
resyncPeriod: resyncPeriod,
clock: realClock,
}
r.setExpectedType(expectedType)
return r
}
// Run repeatedly uses the reflector's ListAndWatch to fetch all the
// objects and subsequent deltas.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(2).Infof("Starting reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.BackoffUntil(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.backoffManager, true, stopCh)
klog.V(2).Infof("Stopping reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
}
上面可以看到在 NewReflector 的时候将 ListerWatcher 和 queue 传了过来,并在调用 NewNamedReflector 函数时分别赋值给了 listerWatcher 和 store, 而当调用到 Run 函数的时候,就通过调用 ListAndWatch 函数进行核心操作。
下面我们来看看 ListAndWatch 的具体实现逻辑:
// ListAndWatch first lists all items and get the resource version at the moment of call,
// and then use the resource version to watch.
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
klog.V(3).Infof("Listing and watching %v from %s", r.expectedTypeName, r.name)
var resourceVersion string
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
if err := func() error {
initTrace := trace.New("Reflector ListAndWatch", trace.Field{"name", r.name})
defer initTrace.LogIfLong(10 * time.Second)
var list runtime.Object
var paginatedResult bool
var err error
listCh := make(chan struct{}, 1)
panicCh := make(chan interface{}, 1)
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
// Attempt to gather list in chunks, if supported by listerWatcher, if not, the first
// list request will return the full response.
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
switch {
case r.WatchListPageSize != 0:
pager.PageSize = r.WatchListPageSize
case r.paginatedResult:
// We got a paginated result initially. Assume this resource and server honor
// paging requests (i.e. watch cache is probably disabled) and leave the default
// pager size set.
case options.ResourceVersion != "" && options.ResourceVersion != "0":
// User didn't explicitly request pagination.
//
// With ResourceVersion != "", we have a possibility to list from watch cache,
// but we do that (for ResourceVersion != "0") only if Limit is unset.
// To avoid thundering herd on etcd (e.g. on master upgrades), we explicitly
// switch off pagination to force listing from watch cache (if enabled).
// With the existing semantic of RV (result is at least as fresh as provided RV),
// this is correct and doesn't lead to going back in time.
//
// We also don't turn off pagination for ResourceVersion="0", since watch cache
// is ignoring Limit in that case anyway, and if watch cache is not enabled
// we don't introduce regression.
pager.PageSize = 0
}
list, paginatedResult, err = pager.List(context.Background(), options)
if isExpiredError(err) {
r.setIsLastSyncResourceVersionExpired(true)
// Retry immediately if the resource version used to list is expired.
// The pager already falls back to full list if paginated list calls fail due to an "Expired" error on
// continuation pages, but the pager might not be enabled, or the full list might fail because the
// resource version it is listing at is expired, so we need to fallback to resourceVersion="" in all
// to recover and ensure the reflector makes forward progress.
list, paginatedResult, err = pager.List(context.Background(), metav1.ListOptions{ResourceVersion: r.relistResourceVersion()})
}
close(listCh)
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
// We check if the list was paginated and if so set the paginatedResult based on that.
// However, we want to do that only for the initial list (which is the only case
// when we set ResourceVersion="0"). The reasoning behind it is that later, in some
// situations we may force listing directly from etcd (by setting ResourceVersion="")
// which will return paginated result, even if watch cache is enabled. However, in
// that case, we still want to prefer sending requests to watch cache if possible.
//
// Paginated result returned for request with ResourceVersion="0" mean that watch
// cache is disabled and there are a lot of objects of a given type. In such case,
// there is no need to prefer listing from watch cache.
if options.ResourceVersion == "0" && paginatedResult {
r.paginatedResult = true
}
r.setIsLastSyncResourceVersionExpired(false) // list was successful
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
return nil
}(); err != nil {
return err
}
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
for {
// give the stopCh a chance to stop the loop, even in case of continue statements further down on errors
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
// We want to avoid situations of hanging watchers. Stop any wachers that do not
// receive any events within the timeout window.
TimeoutSeconds: &timeoutSeconds,
// To reduce load on kube-apiserver on watch restarts, you may enable watch bookmarks.
// Reflector doesn't assume bookmarks are returned at all (if the server do not support
// watch bookmarks, it will ignore this field).
AllowWatchBookmarks: true,
}
// start the clock before sending the request, since some proxies won't flush headers until after the first watch event is sent
start := r.clock.Now()
w, err := r.listerWatcher.Watch(options)
//...........................................
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
//...........................................
return nil
}
}
}
// watchHandler watches w and keeps *resourceVersion up to date.
func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
eventCount := 0
// Stopping the watcher should be idempotent and if we return from this function there's no way
// we're coming back in with the same watch interface.
defer w.Stop()
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
if !ok {
break loop
}
if event.Type == watch.Error {
return apierrors.FromObject(event.Object)
}
if r.expectedType != nil {
if e, a := r.expectedType, reflect.TypeOf(event.Object); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected type %v, but watch event object had type %v", r.name, e, a))
continue
}
}
if r.expectedGVK != nil {
if e, a := *r.expectedGVK, event.Object.GetObjectKind().GroupVersionKind(); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected gvk %v, but watch event object had gvk %v", r.name, e, a))
continue
}
}
meta, err := meta.Accessor(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
continue
}
newResourceVersion := meta.GetResourceVersion()
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Deleted:
// TODO: Will any consumers need access to the "last known
// state", which is passed in event.Object? If so, may need
// to change this.
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
case watch.Bookmark:
// A `Bookmark` means watch has synced here, just update the resourceVersion
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
eventCount++
}
}
watchDuration := r.clock.Since(start)
if watchDuration < 1*time.Second && eventCount == 0 {
return fmt.Errorf("very short watch: %s: Unexpected watch close - watch lasted less than a second and no items received", r.name)
}
klog.V(4).Infof("%s: Watch close - %v total %v items received", r.name, r.expectedTypeName, eventCount)
return nil
}
这个函数则实现了上述描述的 Reflector 的主要功能,List Watch API 资源,并将结果添加到 DeltaFIFO 队列中。
Controller 源码分析
对于 Controller 部分,则是取出从 Reflector 部分添加到 DeltaFIFO 队列中数据,并进行处理。
// `*controller` implements Controller
type controller struct {
config Config
reflector *Reflector
reflectorMutex sync.RWMutex
clock clock.Clock
}
// Run begins processing items, and will continue until a value is sent down stopCh or it is closed.
// It's an error to call Run more than once.
// Run blocks; call via go.
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
defer wg.Wait()
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
}
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}
从 controller 结构的定义来看,它包含了一个 Reflector 部分,然后在 Run 函数里,可以看到创建了一个 Reflector 对象,并调用了 Reflector 实例的 Run 函数,并调用 c.processLoop 函数进行数据的处理。具体细节请参考 sharedProcessor 分析
Indexer 源码分析
- Store : 是一个通用对象存储和处理接口。
- Indexer : Indexer 扩展了多个索引的 Store,并限制每个累加器只保存当前对象(删除后为空)。
- cache : 根据 ThreadSafeStore 和关联的 KeyFunc 实现的 Indexer。
- ThreadSafeStore : 是一个允许对存储后端进行并发索引访问的接口。它类似于 Indexer,但不(必须)知道如何从给定对象中提取存储键。
- threadSafeMap : 实现了 ThreadSafeStore。
下面为具体的类图展示:
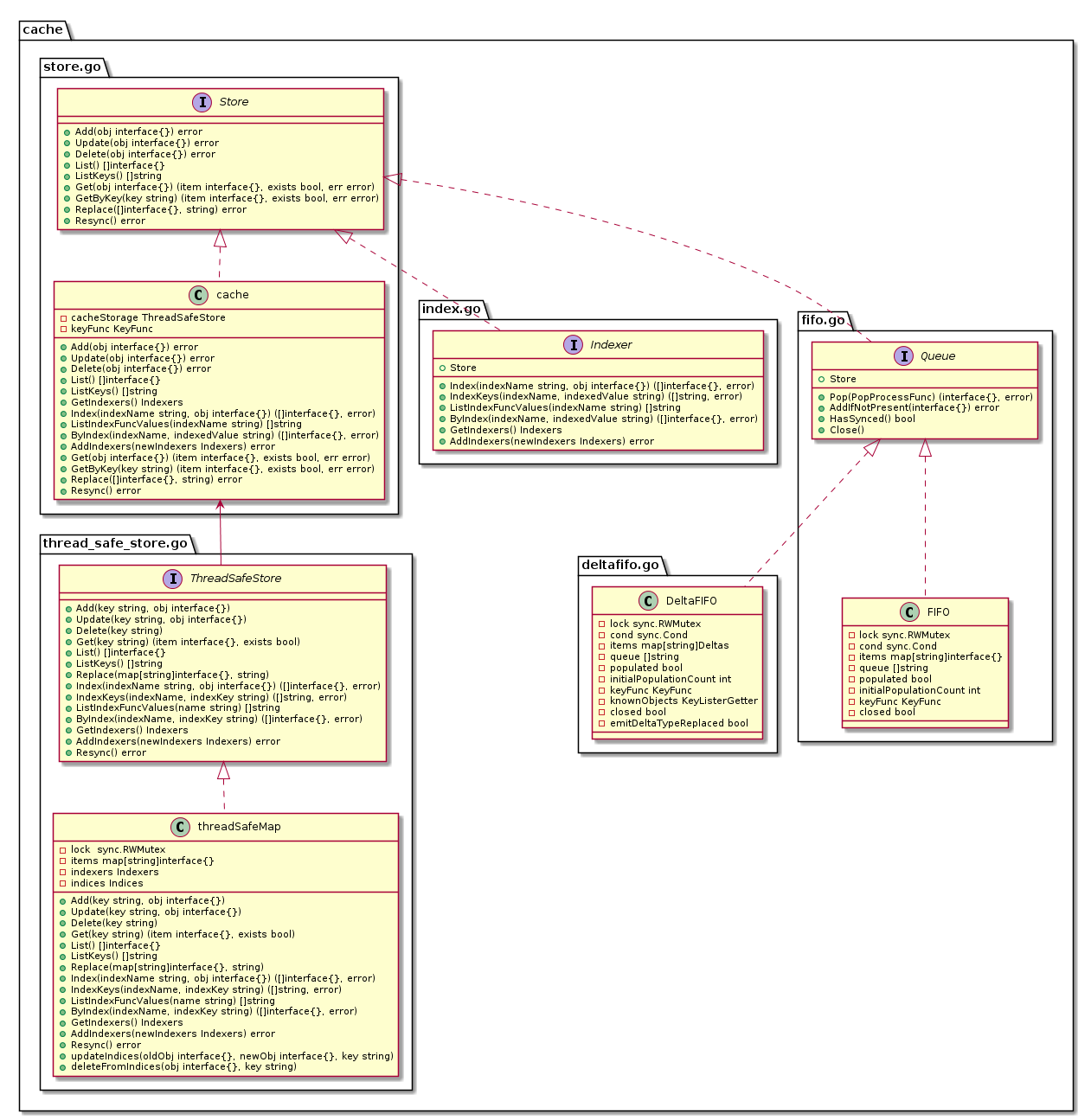
threadSafeMap 源码分析
threadSafeMap 类中包含下面三个属性:
items map[string]interface{}保存所有数据的 map 结构。indexers Indexers通过一个名字映射一个 IndexFunc 索引处理函数。indices Indices通过一个名字映射一个 Index。
下面是 threadSafeMap 结构的源码定义:
// threadSafeMap implements ThreadSafeStore
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
下面是 Indexers, Indices and Index 的源码定义:
// IndexFunc knows how to compute the set of indexed values for an object.
type IndexFunc func(obj interface{}) ([]string, error)
// Index maps the indexed value to a set of keys in the store that match on that value
type Index map[string]sets.String
// Indexers maps a name to a IndexFunc
type Indexers map[string]IndexFunc
// Indices maps a name to an Index
type Indices map[string]Index
这是一个 threadSafeMap 存储结构的示例图:
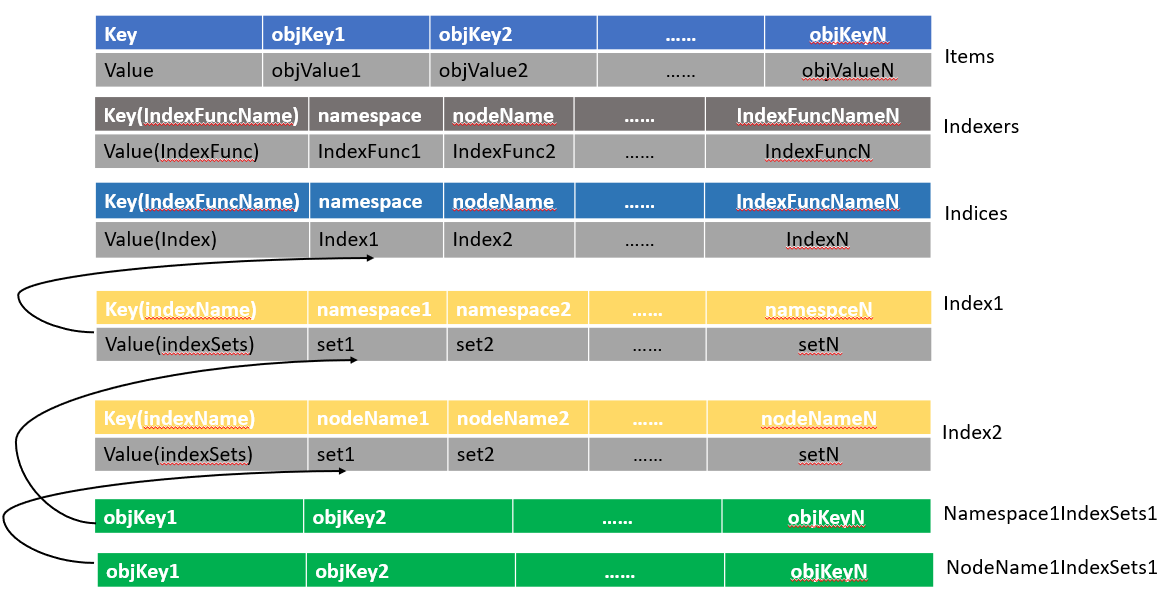
最后以添加一个新的对象到 threadSafeMap 为例,分析具体需要哪些操作。
首先列出源码以供参考:
func (c *threadSafeMap) Add(key string, obj interface{}) {
c.lock.Lock()
defer c.lock.Unlock()
oldObject := c.items[key]
c.items[key] = obj
c.updateIndices(oldObject, obj, key)
}
// updateIndices modifies the objects location in the managed indexes, if this is an update, you must provide an oldObj
// updateIndices must be called from a function that already has a lock on the cache
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
// if we got an old object, we need to remove it before we add it again
if oldObj != nil {
c.deleteFromIndices(oldObj, key)
}
for name, indexFunc := range c.indexers {
indexValues, err := indexFunc(newObj)
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
index := c.indices[name]
if index == nil {
index = Index{}
c.indices[name] = index
}
for _, indexValue := range indexValues {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
set.Insert(key)
}
}
}
从上面代码可以总结出下面几个步骤:
- 从 items 中获取旧的对象值,并将新的对象添加到 items 中指定键值的位置。
- 将新加入对象的键值更新到索引中。
- 如果旧的对象存在,则将其从索引中删除,否则进行下一步。
- 迭代 indexers 进行新对象的索引处理。
- 通过 indexers 中的 indexFunc 处理新对象,找到相应的 indexValues。
- 使用 indexer 的 name 从 indices 中找到对应的 index。如果对应的 index 是空,则创建一个新的 index。
- 迭代 indexValues 进行 index 处理。
- 通过 indexValue 在 index 中找到对应的 set, 如果 set 不存在,则创建一个新的 set。并添加到 index 中。
- 添加新对象的键值到 set 中。
- 返回第 5 步,直到迭代完成。
- 返回第 2 步,直到迭代完成。
参考文章
- Source code
- Client-Go informer 机制
- informer 之 store 和 index
- Kubernetes Client-Go Informer 实现源码剖析
- client-go package Informer source code analysis
- kube-controller-manager 源码分析(三)之 Informer 机制
- Indexer
- 分块传输编码
- k8s client-go informer 源码分析